
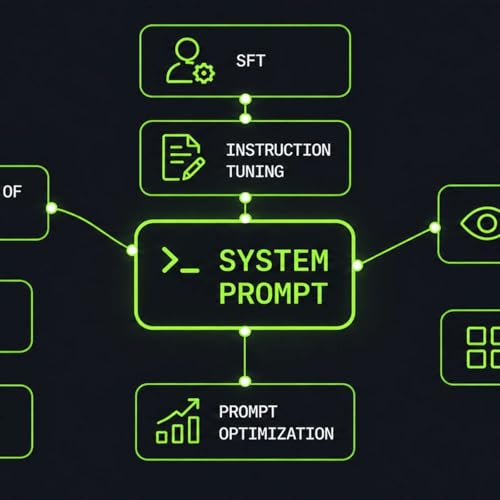
System Prompts Under the Hood: How LLMs Learn to Follow Instructions
Artikel konnten nicht hinzugefügt werden
Der Titel konnte nicht zum Warenkorb hinzugefügt werden.
Der Titel konnte nicht zum Merkzettel hinzugefügt werden.
„Von Wunschzettel entfernen“ fehlgeschlagen.
„Podcast folgen“ fehlgeschlagen
„Podcast nicht mehr folgen“ fehlgeschlagen
System Prompts Under the Hood: How LLMs Learn to Follow Instructions
-
Gesprochen von:
-
Von:
Über diesen Titel
This story was originally published on HackerNoon at: https://hackernoon.com/system-prompts-under-the-hood-how-llms-learn-to-follow-instructions.
Deep dive into LLM system messages: how models parse and follow them, what they mean for app security, and best practices for writing and optimization.
Check more stories related to machine-learning at: https://hackernoon.com/c/machine-learning. You can also check exclusive content about #ai, #llm, #ai-engineering, #ai-system-design, #agentic-systems, #ai-agents, #deep-dive, #generative-ai, and more.
This story was written by: @loneas. Learn more about this writer by checking @loneas's about page, and for more stories, please visit hackernoon.com.
System prompts define how LLM agents behave, use tools, follow policies, and prioritize instructions. Understanding how they work under the hood helps developers write better prompts, evaluate them systematically, and reduce security risks such as jailbreaks and prompt injection. This article covers how LLMs see system prompts, how they are trained to follow instructions, and what consequences this has.